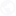Artificial Intelligence Sued for Open Source Piracy
Copilot, an artificial intelligence-based system for automatically generating source code, has just been sued for $9 billion in damages for “software piracy.” This amount is based on a calculation from 3.5 million copyright infringements allegedly committed by the system, at the compensation of $2,500 damages per case. What is the background?

Artificial intelligence (AI) is now appearing in all areas of life, and its capabilities are often remarkable. AI also works in software development. The idea is: the developer tells the system what is required, and the code is then automatically created. The goals are increased productivity, time savings and high-quality code.
According to a 2023 study by McKinsey, which examines the impact of generative AI on various industries and business functions, AI technologies can lead to an annual increase in productivity of up to USD 4.4 trillion. Across all industries, software development is mentioned as the area where AI will have one of the most significant impact.
AI develops software
There are several approaches to AI in software development: Some time ago, Google published the Alphacode project: The system finds solutions to problems that require a combination of critical thinking, logic, algorithms, coding and natural language understanding. It has been used to achieve better than average results in programming competitions. The system was trained using github and also data from programming competitions.
IBM is also experimenting with software development through AI: The “Watson Code Assistant” generates code from a natural language query. Red Hat and IBM have announced a cooperation; the project, called “Project Wisdom”, is simplify cloud management via natural language input.
Amazon is working on “Codewhisperer”, the goal here is also to increase developer productivity. The software writes and reviewes code and comments and makes recommendations. So far, the system is able to handle Java, JavaScript and Python.
cursor.sh is an AI-driven code editor “that lets you move faster”. You can use Cursor to edit code in natural language, fix runtime errors and locate hard-to-find code, or translate code from one language to another. Cursor is based on OpenAI’s LLM.
Copilot is an artificial intelligence-based tool developed by GitHub and OpenAI, with great financial support from Microsoft. It can be integrated directly into a development environment and assists with code completion. Copilot provides suggestions based on text input from the user. Copilot can be used for small suggestions, such as up to the end of a line, but can also suggest larger blocks of text, such as the entire body of a function.
Copilot is powered by an AI that was trained using source code from the Internet. It is a modified version of the system that also underlies ChatGPT. It was based on tens of millions of public programs with tens of billions of lines of code, including from github. Many open source projects are published there.
If Copilot finds a request which is similar to what it has already seen on github, it can generate a response. The response is generated based on the input from all “learned” programs.
The following image shows an example: as soon as a developer enters the characters marked in blue, Copilot suggests all the rest of the code. This is shown on the left-hand side of the graphic.
Why can Copilot do that? The system was taught using data from the Internet. If so, then the training data can possibly be found. This is indeed the case: An algorithm by Mr. Davis can be quickly found on github, shown on the right-hand side.
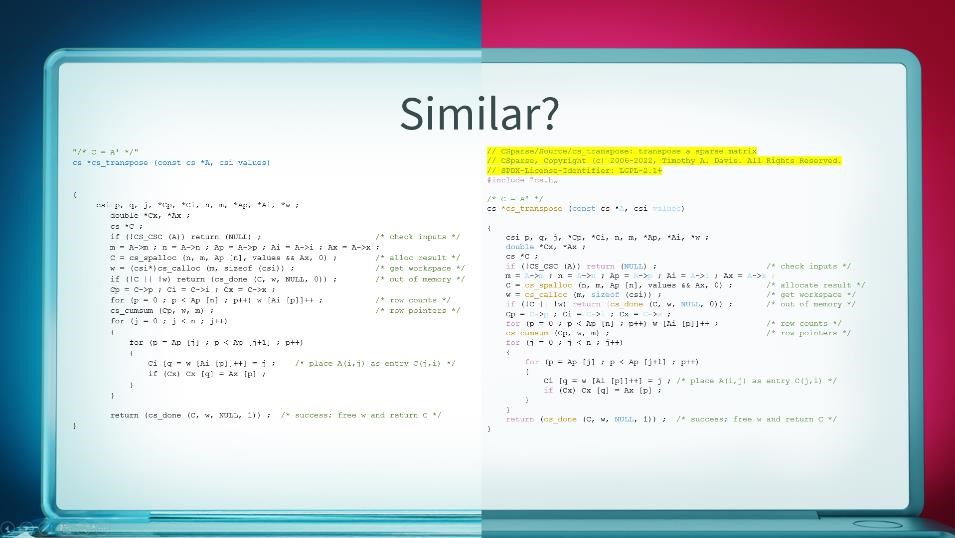
Comparing the Copilot edition with the original shows that the entire code is identical. However, in the original there is a short comment, a copyright, and a license. These are missing in the Copilot output. And there are a lot of this kind of examples circulating on the Internet.
Copilot can thus be made to generate code 1:1 from identifiable sources. However, the way Copilot has been trained means that information about the origin of the code – e.g. author or license – is no longer available. Tim Davis, a professor at a Texas university, has published numerous examples of this.
Controversial discussion
This has led to quite a bit of discussion.
First of all, it’s about how the system was trained: The training data comes from github, among other sources. Most of the open source software packages are released under licenses that give users certain rights and impose certain obligations. As users, you must comply with those licenses or use the code under a license exception (e.g., under a “fair use” exception). If Microsoft and OpenAI wanted to use these packages under their respective open source licenses, Microsoft and OpenAI would have had to publish a lot of attribution/copyrights/license, as this is a minimum requirement of almost any open source license. However, no attribution is apparent. Therefore, Microsoft and OpenAI must be relying on a fair use argument. In fact, we know this is so because former GitHub CEO Nat Friedman claimed during the Copilot technical preview that “training machine learning systems on public data is fair use.”
However, not everyone shares this opinion: The Software Freedom Conservancy (SFC) requested legal evidence from Microsoft, but has not received any. SFC notes in this regard that there is no case in the U.S. that clearly clarifies the impact of AI training on fair use.
Users also have a problem: We have just seen that Copilot can be made to output code from identifiable repositories. Using this code obligates one to comply with the license. However, a side effect of the Copilot design is that information about the origin of the code – author, license, etc. – is no longer available. How can Copilot users comply with the license if they don’t even know it exists? Microsoft characterizes the output of Copilot as a set of code “suggestions.” Microsoft does not claim any rights to these suggestions. But Microsoft also makes no warranties of non-infringement of intellectual property of others of the generated code. Once you accept a Copilot proposal, it all becomes your responsibility. This is difficult to do: to determine potential copyright holders or licenses requires tools that can recognize code from open source projects.
Furthermore, there are privacy concerns: The Copilot service is cloud-based and requires constant communication with the GitHub Copilot servers. This architecture has raised concerns because every keystroke is transmitted to Copilot.
Another issue is security concerns. In a study by IEEE on “Security and Privacy 2022”, code generated by Copilot was checked for the most important known code vulnerabilities, such as “cross-site scripting” or “path traversal”. It was found that of the scenarios and programs examined, more than one third of the code suggestions contained vulnerabilities – just as Copilot had learned from github.
Microsoft explains, “As a user, you are responsible for ensuring the safety and quality of your code. We recommend that you take the same precautions when using code generated by GitHub Copilot that you would when using code you didn’t write yourself. These precautions include testing, scanning for intellectual property, and finding security vulnerabilities.”
On a completely different note, Copilot is like an obscure interface to a large amount of open source code. Many developers feel this cuts off the relationship between open source authors and users. Copilot is like a fenced garden that keeps developers from discovering or participating in traditional open source communities. With Copilot, open source users never have to know who developed their software. They never have to interact with a community. They never have to make a contribution. Some authors worry that Copilot will “starve” these communities. User engagement will shift to Copilot, away from the open source projects themselves. This will be a permanent loss for open source.
What are the direct consequences?
Back in July 2021, the Free Software Foundation (FSF) issued a call for white papers on philosophical and legal issues related to Copilot.
In June 2022, the Software Freedom Conservancy announced that it would stop all uses of GitHub in its own projects, and accused Copilot of ignoring the code licenses used in the training data.
The developers of Copilot have also reacted: A new feature has now been built directly into Copilot: There is now a way to tell the system not to include obvious open-source snippets. The technique is simple: as soon as the AI generated code becomes longer than 150 characters, it will no longer be output. We have checked this, and it is indeed the case: no more obviously copied open source code appears in the examples tested.
In addition, the terms and conditions have been expanded: there is now a passage that Copilot’s outputs may be subject to licenses from third parties.
GitHub has announced that there will be another new feature later this year that will display licenses and authors when open source is suggested as code. Or, if the code occurs in many repositories, provides links to all occurrences.
Amazon announced that, unlike GitHub Copilot, their tool recognizes code snippets from the training data and then highlights the license of the original function. This allows developers to decide whether or not to use them. Codewhisperer would also checks code for potential security issues. We tried this out as well: However, this function is only available in the commercial version of CodeWhisperer; the free version lacks this capability.
lawsuit
The above findings and observations promptly led to legal action against OpenAI: In November 2022, a law firm filed a law suit against Copilot in the United States. The law firm is challenging Copilot’s legality based on several claims, ranging from breach of contract with GitHub users to privacy violations for sharing personal data.
Charges include:
- copyright infringement and violation of open source license terms:
By training their AI systems on public GitHub repositories, the defendants have violated the rights of a large number of authors who have posted code or other works on GitHub under certain open source licenses. Specifically, eleven popular open source licenses, all of which require attribution of the author’s name and copyright, including the MIT License, the GPL, and the Apache License. - violation of GitHub’s terms of use and privacy policy:
For example, the removal of copyright management information was prohibited.
As well as several other side points.
In January, Microsoft, GitHub, and OpenAI had filed motions to dismiss the plaintiffs’ complaint. In March, the plaintiffs filed an opposition to these motions to dismiss. In May, the lawsuit was finally allowed to proceed. Of particular significance, the court completely rejected the defendants’ efforts to dismiss two of the plaintiffs’ most important claims, namely infringement of open source licenses and removal of copyright management information.
This lawsuit is particularly interesting because it is one of the first to explore the legal limits of current artificial intelligence, which uses available information for training and creates some sort of composite of that material. If the lawsuit is successful, it could decrease speed on the development of such software.
Summary
Tools based on artificial intelligence can efficiently produce high-quality code. The way in which the Copilot system in particular has been trained and the output of code it creates has raised questions. There is a controversial discussion on this, and the lawsuit is based on this.
Copilot defends itself with the argument that the developer are responsible for functionality, security and compliance of the code.
The whole topic is incredibly exciting because it generally raises the question: How and with what data may an artificial intelligence be trained? This may have implications for the development of future AI systems.
Ultimately, the work of software developers will change seriously in the future due to the use of AI: AI will take over and accelerate some tasks of SW development.
 Previous Post
Previous Post Next Post
Next Post