Copilot, ein auf künstlicher Intelligenz beruhendes System zur automatischen Erzeugung von Quellcode, wurde gerade auf 9 Mrd $ Schadenersatz wegen „Software-Piraterie“ verklagt. Dies berechnet sich aus 3,5 Millionen Copyrightverletzungen, die das System begangen haben soll, zu jeweils der Kompensation von 2.500 $ Schadenersatz pro Fall. Was ist der Hintergrund?

Künstliche Intelligenz (KI) taucht mittlerweile in allen Lebensbereichen auf, deren Fähigkeiten sind oft bemerkenswert. KI funktioniert auch bei der Entwicklung von Software. Die Idee ist: Der Entwickler teilt dem System mit was er möchte, und der Code wird danach automatisch erstellt oder ergänzt. Ziele sind Produktivitätssteigerung, Zeitersparnis und qualitativ hochwertiger Code.
Nach einer Studie von McKinsey aus dem Jahre 2023, welche die Auswirkung von generativer KI auf unterschiedliche Industrien und Geschäftsfunktionen untersucht, können KI-Technologien zu einem jährlichen Produktivitätszuwachs von bis zu 4,4 Billionen US-Dollar führen. Softwareentwicklung wird dabei über alle Industrien hinweg als derjenige Bereich erwähnt, auf den KI mit die gravierendsten Auswirkungen haben wird.
KI entwickelt Software
Für KI in der Softwareentwicklung gibt es mittlerweile viele Ansätze: Schon vor einiger Zeit gab es Veröffentlichungen von Google zum Projekt Alphacode: Das System findet Lösungen zu Problemen, welche eine Kombination aus kritischem Denken, Logik, Algorithmen, Kodierung und Verständnis der natürlichen Sprache erfordern. In Programmierwettbewerben konnten damit besser als durchschnittliche Ergebnisse erzielt werden. Trainiert wurde das System mit github und auch Daten aus Programmierwettbewerben.
Auch IBM experimentiert mit der Softwareentwicklung durch KI: Der „Watson Code Assistant“ generiert Code mit geeigneter Syntax aus einer natürlichsprachlichen Anfrage. Red Hat und IBM haben eine Kooperation bekannt gegeben, das „Project Wisdom“ getaufte Vorhaben soll über natürliche Spracheingabe funktionieren und so das Cloud-Management vereinfachen.
Amazon arbeitet an „Codewhisperer“, Ziel ist auch hier die Produktivität der Entwickler zu steigern. Die Software untersucht den Code sowie die Kommentare und gibt Empfehlungen. Das System beherrscht bisher Java, JavaScript und Python.
cursor.sh ist ein KI-gesteuerter Code-Editor, „mit dem Sie schneller vorankommen“. Sie können Cursor verwenden, um Code in natürlicher Sprache zu bearbeiten, Laufzeitfehler zu beheben und schwer zu findenden Code zu lokalisieren oder Code von einer Sprache in eine andere zu übersetzen. Cursor basiert auf dem LLM von OpenAI.
Copilot ist ein auf künstlicher Intelligenz beruhendes Werkzeug, das von GitHub und OpenAI entwickelt wurde, mit großer finanzieller Unterstützung von Microsoft. Es kann direkt in eine Entwicklungsumgebung eingebunden werden und unterstützt mit der Vervollständigung von Code. Copilot bietet Vorschläge auf der Grundlage von Texteingaben des Benutzers. Copilot kann für kleine Vorschläge verwendet werden, z. B. bis zum Ende einer Zeile, kann aber auch größere Textblöcke vorschlagen, z. B. den gesamten Körper einer Funktion.
Copilot wird durch eine KI angetrieben, die anhand von Quellcode aus dem Internet trainiert wurde. Es ist eine modifizierte Version des Systems, welches auch ChatGPT zugrunde liegt. Grundlage waren zig Millionen öffentliche Programme mit zig Milliarden Zeilen Code, unter anderem von github. Viele Open Source Projekte sind dort veröffentlicht.
Wenn Copilot eine ähnliche Anfrage findet von dem was es bei github schon gesehen hat, kann es eine Antwort erzeugen. Dazu wird aus allen „gelernten“ Programmen eine mögliche Antwort generiert.
Im folgenden Bild sehen Sie ein Beispiel: Sobald ein Entwickler die in blau markierten Zeichen eingibt, schlägt Copilot den gesamten Rest des Codes vor. Dies ist links dargestellt.
Warum kann Copilot das? Das System wurde anhand von Daten aus dem Internet angelernt. Wenn dem so ist, dann lassen sich eventuell auch die Trainingsdaten finden. Dies ist in der Tat so: Es lässt sich schnell ein Algorithmus von Herrn Davis auf github finden, rechts dargestellt.
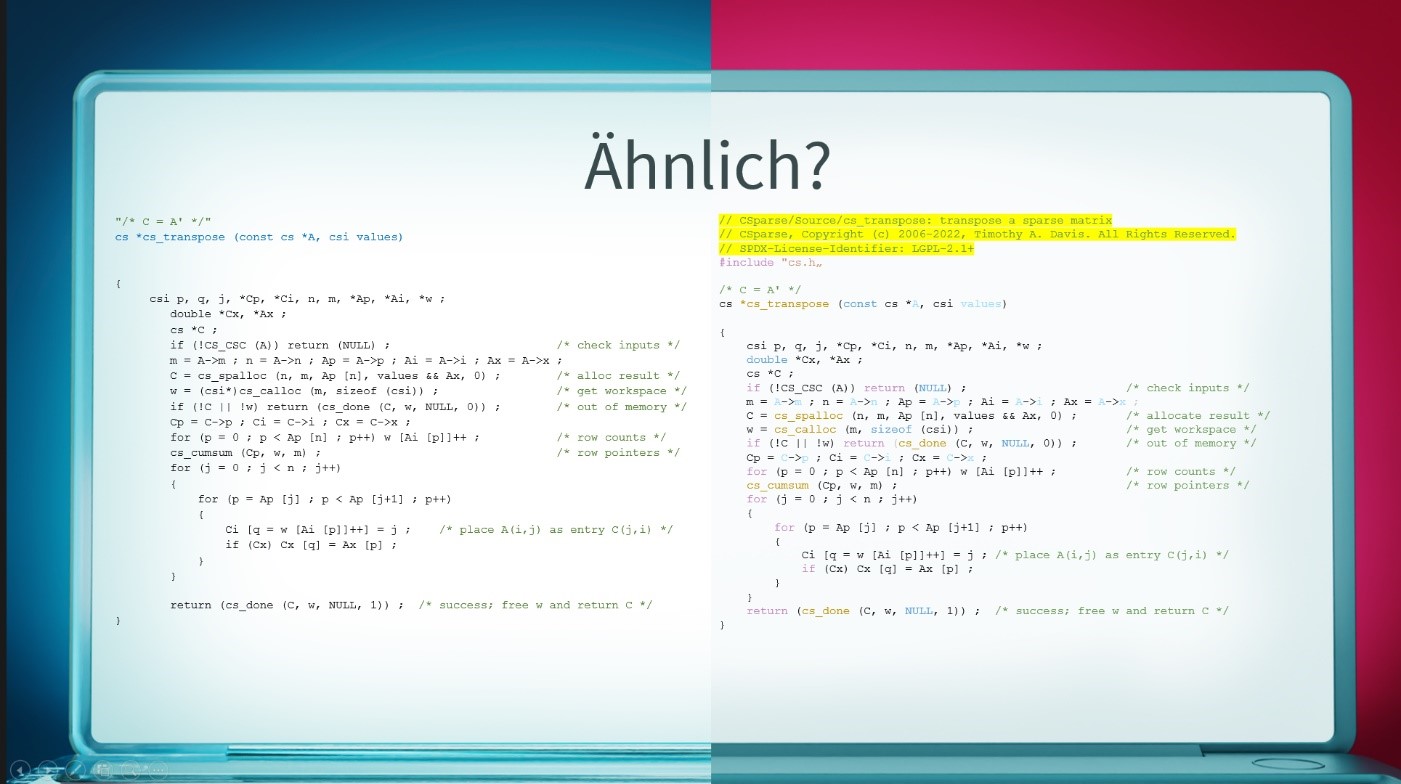
Beim Vergleich zwischen Copilot-Ausgabe und Original zeigt sich, dass der gesamte Code identisch ist. Im Original gibt es aber noch einen kurzen Kommentar, ein Copyright, und eine Lizenz. Diese fehlen bei der Ausgabe von Copilot. Und von dieser Art von Beispielen kursieren eine ganze Menge im Internet.
Copilot kann also dazu gebracht werden, Code 1:1 aus identifizierbaren Repositories zu erstellen. Die Art wie Copilot trainiert wurde führt jedoch dazu, dass Informationen über die Herkunft des Codes – z.B. Autor oder Lizenz – nicht mehr vorhanden sind. Tim Davis, ein Professor einer Hochschule in Texas, hat zahlreiche Beispiele dazu veröffentlicht.
Kontroverse Diskussion
Dies hat zu einer ganzen Reihe von Diskussionen geführt.
Zuerst einmal geht es darum, wie das System trainiert wurde: Die Trainingsdaten kommen unter anderem von github. Die meisten der Open-Source-Softwarepakete werden unter Lizenzen veröffentlicht, die den Nutzern bestimmte Rechte einräumen und bestimmte Pflichten auferlegen. Als Nutzer müssen sie diese Lizenzen einhalten oder den Code im Rahmen einer Lizenzausnahme verwenden (z.B. im Rahmen einer „fair use“ Ausnahme). Wenn Microsoft und OpenAI diese Pakete unter ihren jeweiligen Open-Source-Lizenzen verwenden wollten, hätten Microsoft und OpenAI viele Quellenangaben/Copyrights/Lizenz veröffentlichen müssen, denn dies ist eine Mindestanforderung so ziemlich jeder Open-Source-Lizenz. Es ist jedoch keine Namensnennung ersichtlich. Daher müssen sich Microsoft und OpenAI auf ein Fair-Use-Argument berufen. Tatsächlich wissen wir, dass dies so ist, weil der ehemalige GitHub-CEO Nat Friedman während der technischen Vorschau von Copilot behauptete, dass „das Trainieren von maschinellen Lernsystemen auf öffentlichen Daten Fair Use sei“.
Dieser Meinung folgen jedoch nicht alle: Die Software Freedom Conservancy forderte von Microsoft rechtliche Nachweise, hat jedoch keine erhalten. SFC stellt dazu fest, dass es keinen Fall in den USA gibt, der die Auswirkungen von KI-Training auf die Fair-Use-Nutzung eindeutig klärt.
Ein Problem haben auch die Nutzer. Eben haben wir gesehen, dass Copilot dazu gebracht werden kann, wortwörtlichen Code aus identifizierbaren Repositories auszugeben. Die Verwendung dieses Codes verpflichtet dazu, die Lizenz einzuhalten. Ein Nebeneffekt des Copilot-Designs ist jedoch, dass Informationen über den Ursprung des Codes – Autor, Lizenz usw. – nicht mehr vorhanden sind. Wie können die Nutzer von Copilot die Lizenz einhalten, wenn sie nicht einmal wissen, dass sie existiert? Microsoft charakterisiert die Ausgabe von Copilot als eine Reihe von Code-„Vorschlägen“. Microsoft beansprucht keine Rechte an diesen Vorschlägen. Aber Microsoft gibt auch keine Garantien für die Nicht-Verletzung von geistigen Eigentum von anderen des so erzeugten Codes ab. Sobald Sie einen Copilot-Vorschlag akzeptieren, wird das alles zu Ihrer Aufgabe. Das ist schwierig: Um dies festzustellen, bedarf es Werkzeuge, welche Code aus Open Source Projekten erkennen können.
Weiterhin gibt es Bedenken hinsichtlich des Datenschutzes: Der Copilot-Dienst ist Cloud-basiert und erfordert eine ständige Kommunikation mit den GitHub Copilot-Servern. Diese Architektur hat Besorgnis aufgebracht, denn jeder Tastendruck wird an Copilot übermittelt.
Ein weiterer Punkt sind Sicherheitsbedenken. In einer Studie von IEEE über „Security und Privacy 2022“ wurde von Copilot generierter Code bezüglich der wichtigsten bekannten Code-Schwachstellen geprüft, wie „Cross-Site Scripting“ oder „Path Traversal“. Hierbei wurde festgestellt, dass von den untersuchten Szenarien und Programmen mehr als 1/3 der Codevorschläge Schwachstellen enthielten – so wie Copilot den Code eben von github gelernt hatte.
Microsoft erläutert dazu: „Sie als Nutzer sind dafür verantwortlich, die Sicherheit und Qualität Ihres Codes zu gewährleisten. Wir empfehlen Ihnen, bei der Verwendung von Code, der von GitHub Copilot generiert wurde, dieselben Vorsichtsmaßnahmen zu ergreifen, die Sie auch bei der Verwendung von Code ergreifen würden, den Sie nicht selbst geschrieben haben. Zu diesen Vorsichtsmaßnahmen gehören Tests, das Scannen nach geistigem Eigentum, und das Aufspüren von Sicherheitsschwachstellen.“
Noch ein ganz anderer Aspekt: Copilot ist wie eine undurchsichtige Schnittstelle zu einer großen Menge an Open Source Code. Viele Entwickler meinen, dies kappt die Beziehung zwischen Open-Source-Autoren und den Nutzern. Copilot ist wie ein umzäunter Garten, der Entwickler davon abhält, traditionelle Open-Source-Gemeinschaften zu entdecken oder dort teilzunehmen. Mit Copilot müssen Open-Source-Benutzer nie erfahren, wer ihre Software entwickelt hat. Sie müssen nie mit einer Gemeinschaft interagieren. Sie müssen nie einen Beitrag leisten. Einige Autoren befürchten, dass Copilot diese Gemeinschaften „aushungert“. Das Engagement der Nutzer wird sich zu Copilot verlagern, weg von den Open-Source-Projekten selbst. Dies wird ein dauerhafter Verlust für Open Source sein.
Was gibt es für direkte Folgen?
Schon im Juli 2021 veröffentlichte die Free Software Foundation (FSF) einen Aufruf zur Einreichung von Whitepapers zu philosophischen und rechtlichen Fragen im Zusammenhang mit Copilot.
Im Juni 2022 kündigte die Software Freedom Conservancy an, dass sie alle Nutzungen von GitHub in ihren eigenen Projekten einstellen würde, und beschuldigte Copilot, die in den Trainingsdaten verwendeten Codelizenzen zu ignorieren.
Auch die Entwickler von Copilot haben reagiert: Eine neues Feature wurde mittlerweile direkt in Copilot eingebaut: Es gibt nun eine Möglichkeit, dem System mitzuteilen, keine offensichtlichen Open-Source-Schnipsel einzubauen. Die Technik ist simpel: Sobald der automatisch generierte Code länger als 150 Zeichen zu werden droht, wird er nicht mehr ausgegeben. Wir haben das geprüft, und es ist tatsächlich so: In den gezeigten Beispielen taucht kein offensichtlich kopierter Open Source Code mehr auf.
Außerdem wurden die Allgemeinen Geschäftsbedingungen erweitert: Dort findet sich nun ein Passus, dass die Ausgaben von Copilot eventuell Lizenzen von Dritten unterliegen können.
GitHub hat angekündigt, dass es noch dieses Jahr ein weiteres neues Feature geben wird, welches Lizenzen und Urheber einblendet, wenn Open Source als Code vorgeschlagen wird. Oder, falls der Code in vielen Repositories vorkommt, Links auf alle Vorkommen zur Verfügung stellt.
Amazon hat dazu bekannt gegeben, dass ihr Werkzeug im Gegensatz zu GitHub Copilot Codeschnipsel aus den Trainingsdaten erkenne und dann die Lizenz der ursprünglichen Funktion hervorhebe. So können Entwickler entscheiden, ob sie diese verwenden möchten oder nicht. Außerdem prüfe Codewhisperer den Code auf potenzielle Sicherheitsprobleme. Auch das haben wir ausprobiert: Dies gilt aber nur für die kommerzielle Version von CodeWhisperer, in der freien Version fehlt diese Fähigkeit.
Klage
Obige Ausführungen führten prompt zum gerichtlichen Vorgehen gegen OpenAI: Im November 2022 hat eine Kanzlei in den USA Klage gegen Copilot eingereicht. Die Kanzlei stellt die Rechtmäßigkeit von Copilot aufgrund mehrerer Ansprüche in Frage, die von der Verletzung des Vertrags mit den Nutzern von GitHub bis hin zur Verletzung des Datenschutzes für die Weitergabe von personenbezogenen Daten reichen.
Anklagepunkte sind:
- Verletzung von Urheberrechten und Verletzung von Open Source Lizenzbedingungen:
Indem sie ihre KI-Systeme auf öffentlichen GitHub-Repositories trainiert haben, haben die Beklagten die Rechte einer großen Zahl von Urhebern verletzt, die Code oder andere Arbeiten unter bestimmten Open-Source-Lizenzen auf GitHub veröffentlicht haben. Insbesondere 11 populären Open-Source-Lizenzen, die alle die Nennung des Namens des Autors und des Urheberrechts verlangen, darunter die MIT-Lizenz, die GPL und die Apache-Lizenz. - Verletzung der Nutzungsbedingungen und Datenschutzrichtlinien von GitHub :
Beispielsweise sei die Entfernung von Informationen zur Urheberrechtsverwaltung verboten.
Sowie etliche weitere Nebenpunkte.
Im Januar hatten Microsoft, GitHub und OpenAI beantragt, die Klage der Kläger abzuweisen. Im März haben die Kläger gegen diese Anträge auf Klageabweisung Einspruch eingelegt. Im Mai wurde die Klage schließlich zugelassen. Von besonderer Bedeutung ist, dass das Gericht die Bemühungen der Beklagten, zwei der wichtigsten Ansprüche der Klägerinnen abzuweisen, nämlich die Verletzung von Open-Source-Lizenzen und die Entfernung von Urheberrechtsverwaltungsinformationen vollständig zurückgewiesen hat.
Besonders interessant ist diese Klage, da sie eine der ersten ist, welche die rechtlichen Grenzen der aktuellen künstlichen Intelligenz auslotet, welche verfügbare Informationen auswertet und eine Art Kompositum aus Material erstellt, das sie als zuverlässig oder allgemein verwendet ansieht. Sollte die Klage erfolgreich sein, könnte sie die Entwicklung solcher Software bremsen.
Zusammenfassung
Werkzeuge basierend auf künstlicher Intelligenz können effizient qualitativ hochwertigen Code erzeugen. Die Art, wie insbesondere das System Copilot trainiert wurde und wie die Ausgabe von Code aussieht, wirft Fragen auf. Hierzu gibt es eine kontroverse Diskussion, und darauf beruht die Klage.
Copilot verteidigt sich mit dem Argument, dass der Entwickler selbst für Funktionalität, Sicherheit und Compliance des Codes verantwortlich ist.
Das ganze Thema ist unheimlich spannend, weil es im Allgemeinen die Frage aufwirft: Wie und mit welchen Daten darf eine künstliche Intelligenz angelernt werden? Dies kann Auswirkungen auf die Entwicklung zukünftiger KI-Systeme haben.
Letztendlich wird sich zukünftig die Arbeit von Softwareentwicklern durch den Einsatz von KI gravierend ändern: KI wird einige Aufgaben der SW-Entwicklung übernehmen und beschleunigen.